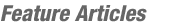
|

By bmerry
TopCoder Member
There are 30 seconds left in the challenge phase. You think you have a challenge, but you're not sure about it. Do you risk it? Do you play it safe? What are the implications for your rating? The right choice could promote you to a new colour. The wrong choice might end that rating increase streak you've been building.
TopCoder publishes their rating algorithm here. However, if you look at this page, your eyes will soon glaze over from all the summations, square roots and statistical functions. This article will attempt to explain, in less precise but more accessible terms, how your rating is adjusted after each match.
I will be using some examples and graphs to try to give a feeling for the numbers involved. These numbers are based on the participants in the TopCoder Open round 1. There are a few areas where the rating algorithm does not provide sufficient detail to create an exact reimplementation (for example, ratings are at some point rounded off to integers, but it is not clear where or how), but the graphs should be accurate enough to demonstrate the principles.
The basics
Apart from the actual rating formulae, there are a few other useful facts you should know about the rating system:
- If you don't open any problems, then your rating will not be adjusted. So if you have registered for an event, even moved to your assigned room and seen the problem values, then remembered that you're supposed to be at your great-aunt's birthday party, you can safely leave. However, if you had opened a problem, you will score 0 for the round and your rating will be damaged.
- The ratings inflate over time. When I first began participating in 2001, there were less than 10 red coders, and the highest rating was around 2500. Today there are about 100 red coders and the highest ratings are well over 3000 (although some of this is due to growth in the number of members). If you stop participating for any length of time, you will drop down the ranks. It is a fairly slow process however, and you would probably have to drop out for a year before the effect became significant.
The formulae
Here we will describe the rating adjustment process, step by step. If you just want some qualitative conclusions, skip ahead to the next section. The rating adjustment process can be broken down into the following steps:
- Each coder in the match is assigned an expected rank, based on a statistical model of coder ability.
- The expected and actual ranks are converted to performance values, using a normal distribution.
- A match rating (my term for PerfAs in the documentation) is calculated by adding the difference of actual and expected performance to the old ranking. This value reflects your performance in this match alone.
- Your new ranking is computed as a weighted average of your old ranking and your match ranking.
- Your rating change is capped.
Volatility
Your rating is a measure of how well you are expected to do on average; in other words, it is a mean value for what I'll call ability (essentially the rating that would correspond to how well you did in any one match). The rating system is based upon a model of your ability, which is a normal distribution with the rating as the mean and volatility as the standard deviation. You can view coders' volatilities on their profile pages. The figure below shows the distribution of volatilities.
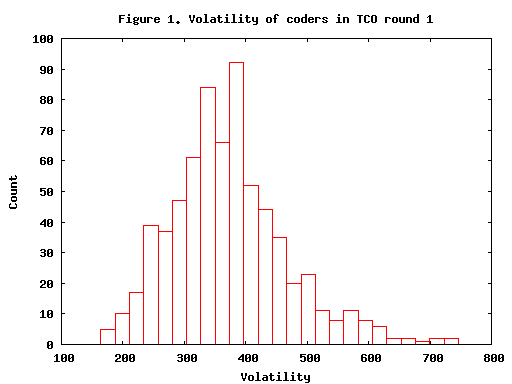
Expected rank and performance
Based on the ratings and volatilities, TopCoder estimates the probability of every coder beating each other coder. From this it is possible to compute the expected rank of each coder i.e., the mean value that the ranking is expected to take. Because of the volatility, the expected rank can differ quite substantially from the seed. It also causes the expected rank to be pulled towards the middle, as shown in figure 2. It is clear that those at the bottom are expected to do better than their seed. What is not so clear from the graph is that that those at the top are expected to do worse than their seed e.g., misof (seeded 1), is only expected to be at rank 8.54. This is probably responsible for the rating inflation over time: a good streak by the number 1 coder will push his rating even higher, even if he doesn't win every time.
The graph also appears to be noiser towards the ends. This is a result of differing volatilities, as the more volatile coders are pulled towards the mean more strongly than others.
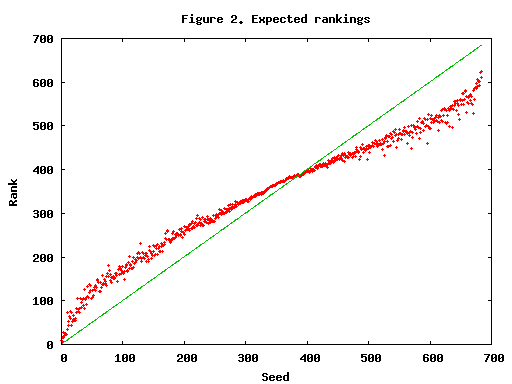
Of course, coming 10th when you were expected to come 2nd is a far more serious thing than coming 110th when you were expected to come 102nd. To compensate for this, TopCoder maps the rankings onto a bell curve to get a performance number. This is essentially what your score would have been, had the scores followed a normal distribution with standard deviation equal to that of the ability model of all the coders (this standard deviation is called the Competition Factor in the TopCoder documentation). Your rating adjustment depends on the difference between your expected and actual performance (computed from the expected and actual rankings).
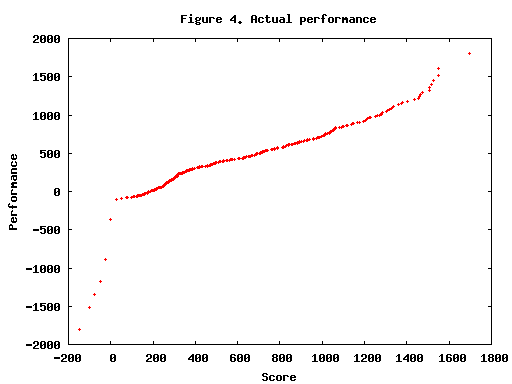
From figure 4, it is clear that a negative score (from failed challenges) has a huge impact on your performance. If you do not expect any of your solutions to survive the challenge phase (or system tests), it is thus very important not to make any challenges that are not a sure thing.
Match rating
The match rating is your old rating, plus the difference between your actual and expected performance. Consequently, if you are at one extreme or the other of the field, your rating can change far more (for a given change in ranking) than if you are in the middle of the field. On the other hand, since scores tend to be more spread out at the ends (particularly the top end), a given change in score will produce a smaller change in ranking and so it should even out.
Weight and cap
Your match rating is intended to reflect your performance in the current match. Of course, that is not a good indicator of overall ability, so your adjusted rating is a weighted average of your old rating and match rating. New coders have a higher weight given to the match rating (since their old rating encapsulates very little history), while more seasoned coders (those who have competed in more matches) have more weight given to their old rating. Figure 4 shows the percentage that is due to the match rating. Note that because the weight does not tend to 0, recent matches generally count more than older matches. In fact, for a seasoned coder the last 10 matches count 90% and the last 20 matches count 99%. Your volatility is adjusted using a similar weighted average, based on your old volatility and the change in your rating.
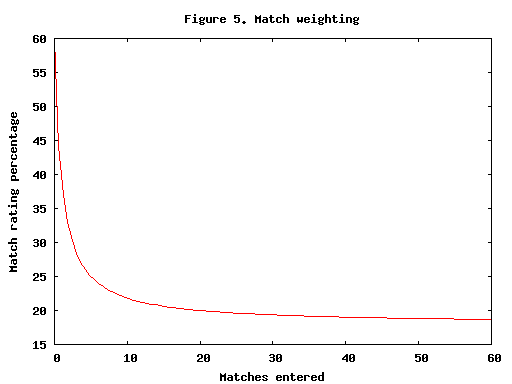
To stabilize the ratings of the higher-rated members (for whom a given change in rank corresponds to a much larger change in rating), members with ratings over 2000 have the weight reduced 10%, and those with a rating over 2500 have the weight reduced 20%.
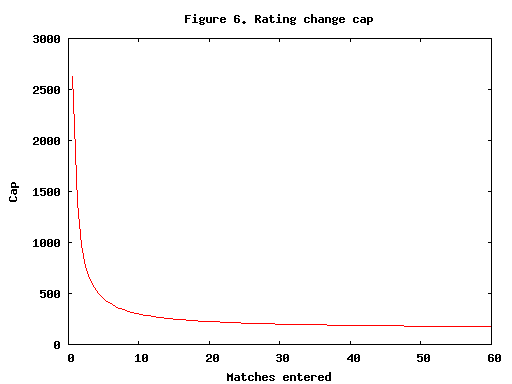
Finally, the ratings are further stabilized by limiting the rating change. Again, new members can change rating rapidly, while long-time members have their ratings stabilized. Figure 5 shows the cap, which is the maximum rating change in either direction.
Conclusions
From the information above, we can draw a number of conclusions:
- Score and room position do not affect rating. Only your rank is relevant.
- The closer you are to the top or the bottom of the seeding, the more sensitive your rating is to your rank.
- The more matches you have competed in, the less your rating will change. However, this effect levels off quickly after 20-30 matches.
- Your more recent matches count more towards your rating. Your last 10 matches count 80-90% for a long-time member, or more if you are a newcomer to TopCoder.