
|
Match Editorial |
Saturday, January 5, 2008
Match summary
1324 coders showed up to the first SRM of 2008, and they were greeted by relatively difficult problem sets.
Division 1 saw a challenging implementation-oriented easy problem, followed by a geometry-based medium problem which gave some coders trouble. The hard problem proved to be difficult and deceptive, as ACRush was the only
coder who ended up with a successful solution. As the only coder to solve all three problems, ACRush won the match by a huge margin, also capturing the #1 algorithm ranking from Petr. Rounding out the top three were Rizvanov_de_xXx who was
aided by three successful challenges and icanadi, who had a roller-coaster of a challenge phase.
Division 2 saw a fairly simple easy problem, but many coders became stuck once they opened the medium (which was also division 1's easy). The hard problem proved to be very conceptually challenging, as only three coders
provided successful solutions. nikolaymakarov won the division by a wide margin as the only competitor to solve all three problems, and second place newcomer Waaagh2 failed his medium problem. Rounding out the top 3 was jbnpaul with 3 successful challenges.
Following a recent trend started by misof, there are exercises at the end of each section that may help you gain a more in-depth understanding of the problems. Feel free to ask questions about them or discuss them in the forums.
The Problems
TrophyShelf

Used as: Division Two - Level One:
Value 250 Submission Rate 690 / 722 (95.57%) Success Rate 601 / 690 (87.10%) High Score saintqdd for 249.15 points (1 mins 39 secs) Average Score 216.67 (for 601 correct submissions)
This problem is solved most easily by realizing that when we're trying to determine if a trophy is visible or not, we only need to know the height of the tallest trophy in front of it. If the current trophy is taller, then it is visible, otherwise it's obstructed. We then perform a possible update of the tallest trophy encountered thus far after determining if the current trophy is visible. A sample java implementation of this approach follows:
public class TrophyShelf {
public int[] countVisible(int[] trophies) {
int[] ret = {1, 1};
int big = trophies[0];
for (int i = 1; i < trophies.length;i++) {
if(trophies[i]>big) ret[0]++;
big=Math.max(big, trophies[i]);
}
big = trophies[trophies.length-1];
for (int i = trophies.length - 2; i >= 0; i--) {
if(trophies[i]>big) ret[1]++;
big=Math.max(big, trophies[i]);
}
return ret;
}
}
CandidateKeys Used as: Division Two - Level Two:
Used as: Division One - Level One:
Value 500 Submission Rate 175 / 722 (24.24%) Success Rate 79 / 175 (45.14%) High Score nikolaymakarov for 364.56 points (18 mins 51 secs) Average Score 238.90 (for 79 correct submissions)
Value 250 Submission Rate 521 / 598 (87.12%) Success Rate 435 / 521 (83.49%) High Score ACRush for 241.35 points (5 mins 24 secs) Average Score 167.69 (for 435 correct submissions)
The low constraints on this problem should be a clear sign that a brute-force solution is intended. The simplest solution (conceptually) to this problem is to generate all possible keys,
and for each one check to see if it's a superkey. If so, we add it to our list of superkeys. Afterwards, we can iterate through each of our superkeys and check to see if any other superkey
is a proper subset of it. If not, then the superkey in question is a candidate superkey.
Determining if a key is a superkey is fairly simple. We just get the Strings formed by our key's attributes for each pair of entries, and if any two entries are the same, then the key is not a superkey.
Generating all keys is a task that is best solved by using bitmasks, which very frequently appear in TopCoder problems, and so are well worth learning about. To do so, I recommend reading bmerry's excellent
bitmask tutorial.
Of course, the solution above can be optimized in a couple of ways. First, assume that we're generating our keys with bitmasks, going from 1 to (1 << n) - 1 in numerical order, and we're keeping track
of all superkeys we've seen before the current one. It turns out that these are the only superkeys that can possibly be subsets of the current superkey. To see why, let's imagine that
the bitmask describing the current key is 001101. It's impossible for this key to be a superset of any key with a numerical value that's greater than it, because to get a key that's a subset of 001101
we must remove one or more '1' bits, and these keys must be numerically smaller than the current key.
For the above algorithm, we must generate all superkeys, and for each one, check if each superkey numerically smaller than it is a subset of it. We can improve this by observing that if we wish to check if
our current superkey is a candidate superkey, we only need to check if any keys formed by removing a single '1' bit from the current key is also a superkey. If so, then the current key is not a candidate superkey.
This observation greatly reduces the time complexity of our algorithm. You can view AdrianKuegel's solution for a clean implementation of this approach.
Exercises:
2.1: Prove why we only need to check if any keys formed by removing a single '1' bit from the current key are superkeys in the above approach.
2.2: Give an O(2^N * (N*M + M log M)) algorithm to solve this problem, noting that comparing two strings of length K is O(K). Here, N is the number of columns of tables and M is the number of rows.
Used as: Division Two - Level Three:
Value 1000 Submission Rate 15 / 722 (2.08%) Success Rate 3 / 15 (20.00%) High Score nikolaymakarov for 570.94 points (29 mins 51 secs) Average Score 505.37 (for 3 correct submissions)
There are several correct approaches to this problem, with varying time complexities. An important observation that's useful in each solution is that if we eventually end up augmenting the subtree rooted at a vertex W and one of
its ancestors V, then we never want to augment the subtree rooted at W before V. This is because augmenting the subtree rooted at V first potentially decreases the amount that the W subtree will need to be augmented by, while still performing the necessary augmentation
to the V subtree.
Solution #1: Dynamic Programming
The result that we wish to compute is F(V,H) which means that we're trying to make the height of the subtree rooted at V to be less than or equal to height as cheaply as possible, and V is currently at level H.
First, let us consider our base case, that is whenever V is a leaf vertex. Here we have two cases: either H <= height, or H > height. For the first case, we have that F(V,H)=0, since there's no need
to augment V's subtree. Otherwise, F(V,H)=1, since we will compute F(V,H) for non-base cases such that the only time that H > height is when H = height + 1.
Now we may try augmenting the subtree rooted at V to be at any level from 1,2,...,H-1 and get the result Ak=(H-K)+F(V,K), where K is V's new level.
Alternatively, if H <= height, we can try not augmenting V, and instead recurse on V's children, which gives the result B=F(V0,H+1)+F(V1,H+1)+...+F(Vm,H+1), where each Vi is a child of V.
Thus, if H > height, then F(V,H)=min{A1,A2,...,AH-1} since we must augment V's subtree. However, if H <= height, then F(V,H)=min(B,min{A1,A2,...,AH-1}),
since we can choose whether or not we wish to augment V's subtree.
A java implementation of this approach that uses memoization follows. Here, adj[V] is a vector of children of vertex V.
int F(int V, int H) {
if (adj[V].size() == 0) return (H < = height) ? 0 : 1;
if (dp[V][H] !=- 1) return dp[V][H];
int ret = 10000000;
for (int i = 1;i < H; i++) {
int res = (H - i) + F(V, i);
ret = Math.min(ret, res);
}
if (H < = height) {
int res = 0;
for(int i = 0; i < adj[V].size(); i++) res += F(adj[V].elementAt(i), H + 1);
ret = Math.min(ret, res);
}
return dp[V][H] = ret;
}
However, we can improve this algorithm by noticing that we only need to try augmenting the subtree rooted at V by a single level, which improves the running time to O(V*height).Solution #2: Greedy
Say we know that vertex V has descendants that are at a level of greater than height. Is there any reason to augment this vertex's descendants rather than augmenting V? The answer is no, because we can reduce potentially many descendants' levels with one augmentation. Therefore, we can repeatedly augment subtrees rooted at vertices that are at level 2 to be at level 1, so long as these subtrees have some vertices that are at a level greater than height.
Exercises:
3.1: Prove why we only need to augment subtrees by a single level in the DP algorithm.
3.2: Give an O(V^2) implementation of the greedy algorithm.
3.3: Solve this problem in O(V) time.
PolygonCover
Used as: Division One - Level Two:
Value 500 Submission Rate 248 / 598 (41.47%) Success Rate 156 / 248 (62.90%) High Score Gassa for 480.43 points (5 mins 46 secs) Average Score 309.30 (for 156 correct submissions)
To solve this problem, we'll use one of the most fundamental and powerful tools in computational geometry: polygon triangulation. Every convex polygon can be decomposed into a set of non-overlapping
triangles, with all three vertices of each triangle lying on the original polygon's vertices. This fact allows us to only consider triangles for covering our points.
We can make implementing this problem easier by noticing that we actually only need to consider triangles that don't contain any points, besides the points that define its vertices. This is true because we can take any triangle
that contains a point in its interior and decompose it into three nonoverlapping triangles whose union has the same area as the original triangle (see the illustration below). This argument can also be extended inductively for triangles that contain several points in their interiors. To simplify
implementation, we can just implement this algorithm assuming that no triangle covers any points besides those at its vertices.
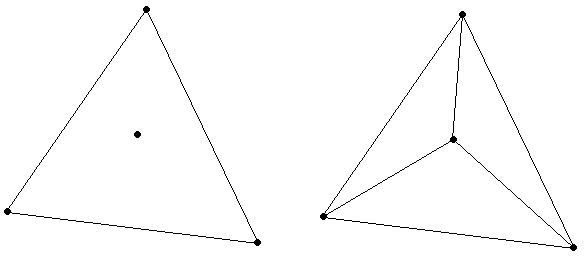
Armed with these observations, we're ready to solve the problem. Our solution will use dynamic programming, where we wish to compute F(P), which is defined as the smallest area of triangles required to cover all points in set P.
To compute F(P), we simply iterate through each triple of points {a,b,c} (such that at least one such point must be covered), and consider F(P-{a,b,c})+area(a,b,c)) as a possible return value. Our final result is the smallest
such value. Of course, if P is the empty set, then we simply return 0. Since there are O(2^n) states, and each state uses O(N^3) iterations, this algorithm runs in O(2^N * N^3).
See Ryan's submission for a nice implementation of this approach.
Though we haven't described how to find the area of a triangle, the best method here is to use the cross-product, as outlined in lbackstrom's geometry tutorial,
which is well worth reading for a variety of concepts on computational geometry.
Exercises:
4.1: Prove why we can assume that no triangle covers any points besides those at its vertices, and still have this algorithm be optimal.
4.2: Prove or disprove: If we allow triples of collinear points, our observations about triangles that contain points in their interiors still holds.
4.3: Solve this problem in O(2^N * N^3), where triples of collinear points are allowed.
4.4: How would our problem change if we were able to use any simple polygon to cover our points?
Used as: Division One - Level Three:
Value 1000 Submission Rate 11 / 598 (1.84%) Success Rate 1 / 11 (9.09%) High Score ACRush for 501.07 points (37 mins 22 secs) Average Score 501.07 (for 1 correct submission)
The main challenge of this problem was avoiding various pitfalls. For complex, multi-layered problems such as this one, it's important to take your time while thinking and make sure you know exactly how your solution will work before you begin coding.
The most common mistake that competitors seemed to make here was not using information gathered on your path in order to correctly compute the probability of being captured in the future. For those unfamiliar with probability theory,
please take the time to read supernova's tutorial.
We can model this problem as a graph theory problem, with rooms as vertices and corridors as edges. We will solve this problem by constructing several mathematical functions, and we'll create efficient algorithms to compute and combine them. Assume there are m agents.
Let's define P(V) to be the probability that we're captured at some point in the future, given that we've visited vertices V=(V0,..,Vk) without being captured.
We will compute this function inductively, so our base case is when Vk=finish, and thus P(V)=0, as we've safely reached the finish room. Now let us examine each neighbor W of Vk
that may eventually lead us to the finish room on a shortest path. If we decide to use vertex W as our next vertex, then there are two ways of being captured: we can either be captured during this second, or sometime after this second. Here, a second
consists of the amount of time that it takes us to traverse the current edge, and arrive at the next vertex.
To compute the probability that we will be captured in the second that we go from Vk to W, we'll require the assistance of three helper functions:
- Define Fa(V,W) to be the number of shortest paths that agent a may take, such that he doesn't visit any vertex in V at the same time that we do, but he does visit vertex W at the same time that we do.
- Define Ca(V,W) to be the number of shortest paths that agent a may take, such that he doesn't visit any vertex in V at the same time that we do, but he traverses edge (Vk,W) at the same time that we go through the same edge in the opposite direction, i.e. (W,Vk).
- Define Ga(V) to be the number of shortest paths that agent a may take, such that he doesn't visit any vertex in V at the same time that we do.
Now we can compute the probability that we will be captured in the second that we go from Vk to W. The number of shortest paths that agent a may take that leads to our capture in this second is Fa(V,W)+Ca(V,W), and so the probability that agent a captures us in this second is Ta(V,W)=(Fa(V,W)+Ca(V,W))/Ga(V). We can use this value to compute the following probabilities:
- The probability of being captured by agent a in the next second: Ta(V,W)
- The probability of not being captured by agent a in the next second: 1-Ta(V,W)
- The probability of not being captured by any agents in the next second: (1-T0(V,W))*(1-T1(V,W))*...*(1-Tm(V,W))
- The probability of being captured by some agent in the next second: H(V,W)=1-(1-T0(V,W))*(1-T1(V,W))*...*(1-Tm(V,W))
Thus, the total probability that we're captured in the future if we visit W next is H(V,W)+(1-H(V,W))*P(V+W). Since we wish to visit the vertex that minimizes this probability, we can finally determine that P(V)=min{H(V,W)+(1-H(V,W))*P(V+W) for all shortest path edges to some vertex W}. Note that our final result is P({}), where {} is the empty set.
Of course, there's a glaring issue with the implementing the above approach: its runtime depends on the number of shortest paths that we may take. However, with a maximum number of 25 vertices, there's under 4,500 shortest paths to consider, meaning that if we can efficiently compute F, C, and G then this approach can work. It turns out that we can indeed compute these functions with simple dynamic programming algorithms. Here, we'll show how to compute F, as computing C and G is similar.
Suppose we wish to compute Fa(V,W). To do this, let's define the function Fa(V,W,U) which will represent the number of shortest paths agent a may take from vertex U to to his destination vertex, such that agent a doesn't visit any vertex in V at the same time as we do, but does visit vertex W at the same time as we do. Note that it assumed that agent a has already taken a shortest path to U, and U lies on some shortest path from agent a's start vertex to his end vertex.
We can also assume that the length of the shortest path from our start vertex to W is the length of the shortest path from agent a's start vertex to vertex W, since Fa(V,W,U)=0 otherwise. To compute Fa(V,W,U), there are three cases to consider:
Case 1: The length of the shortest path from agent a's start vertex to U is the same as the length of the shortest path from agent a's start vertex to W, but U &ne W. Here, Fa(V,W,U)=0, as we've violated the condition that agent a must visit W at the same time that we do.
Case 2: U is agent a's end vertex. Here, Fa(V,W,U)=1, as the only path that we may take is the empty path.
Case 3: Neither of the above. Here, we consider each "shortest path edge" that leads to a vertex T such that the length of the shortest path from our start vertex to T is not the same length of the shortest path from agent a's starting vertex to T. We now recurse on Fa(V,W,T), and add its result to our answer.
C++ code that computes Fa(V,W,U) using memoization follows. Here, vMask is a bitmask of vertices that represents the set V above, agentBegin[a] and agentEnd[a] are the start and end rooms, respectively, for agent a, and onPath[a][U][T] is a boolean value that tells us if edge (U,T) lies on a shortest path from agentBegin[a] to agentEnd[a].
int F(int U, int vMask, int W) {
if (sPath[agentBegin[a]][U] == sPath[agentBegin[a]][W] && U != W) return 0;
if (U == agentEnd[a]) return 1;
if (dp[U] != -1) return dp[U];
int ret = 0;
for (int T = 0; T < n; T++) if((vMask & (1 << T)) == 0 && onPath[a][U][T]) ret += F(T,vMask,W);
return dp[U] = ret;
}
Another solution to this problem is found by observing that our problem is equivalent to the following: "Find a fixed shortest path from start to finish such that the probability of being captured is smallest."
Further, the "events" of being captured by specific agents are independent from one another, so it suffices to compute the probabilies of being captured by each agent individually. Thus, if P(V,a) represents the probability
of being captured on our fixed path V by agent a, then the probability of being captured on path V is 1-(1-P(V,0))*(1-P(V,1))*...*(1-P(V,m)). P(V,m) can be computed via dynamic programming, but its implementation is left as an exercise to the reader.Exercises:
5.1: Prove an exact upper bound on the maximum number of shortest paths possible between start and finish in an input graph for this problem.
5.2: Generalize exercise 5.1 to solve the following problem: Given a positive integer N, output an undirected graph with N vertices with unit-weight edges such that, for some pair of vertices, the number of shortest paths between them is maximum.
5.3: Prove that the "fixed shortest path" formulation of this problem is equivalent to the original problem.
5.4: For the "fixed shortest path" formulation of this problem, show that each agent may be treated independently when computing the probability of being captured.
5.5: Can you use conditional probabilities to provide a solution to this problem that generates your path one vertex at a time?
